首 页
首 页 关于我们
关于我们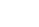 新闻资讯
新闻资讯 行业政策
行业政策 企业评估
企业评估 会员中心
会员中心 协会刊物
协会刊物 人力资源
人力资源 合作交流
合作交流启英泰伦联合启明云端推出离在线语音大模型方案

01
支持基于DNN的本地语音唤醒及识别
针对设备的各项功能控制,无需按键,无需联网,通过该方案可直接进行本地离线语音唤醒和识别。数据无需上传云端进行分析和决策,大大提升了响应速度。
02
支持基于DNN的端点检测
采用先进的端点检测(VAD)技术,通过深度学习与硬件加速的融合设计,在稳态噪声和非稳态噪声环境下均能精准识别人声起始点和终点。仅在检测到人声时进行唤醒,其余时间保持低功耗休眠状态,避免了云端一直监听环境声音,将全部音频上传云端分析带来的高带宽和流量消耗。其响应速度达到毫秒级,作为云端大模型的 “智能哨兵”,为后续的语音处理流程提供了高效、精准的支持。
03
支持基于DNN的语音降噪
采用基于DNN的深度学习语音降噪技术,使得该方案具备更强的自适应性和泛化能力,能够在不同的噪音环境中保持优异的降噪效果,为云端大模型提供了更干净的语音,极大提升了云端大模型的语音识别准确率。
04
支持基于DNN的回声消除打断
基于自适应线性滤波联合基于深度学习的非线性滤波的回声消除方案可有效抑制回声,且能做到实时打断,让用户无需漫长等待即可继续进行语音指令输入,保障了用户体验的流畅性与即时性。
05
支持基于DNN的声源定位
基于麦克风阵列与波束成形算法,实现多场景下的指向性交互,提升人机交互的自然性和人性化。例如,在机器人或智能玩具中,设备可根据声源方向转头或移动,不仅增强了产品的可玩性与趣味性,还为用户带来更具沉浸感的交互体验。
06
支持多语种
启英泰伦自主开发多个小语种模型,支持汉语、英语、日语等多种语言输入,能够满足不同地区、不同语言背景用户的多样化需求,为产品的国际化推广奠定了坚实基础。